这篇文章上次修改于 1407 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
Content: # 1 NAT 原理
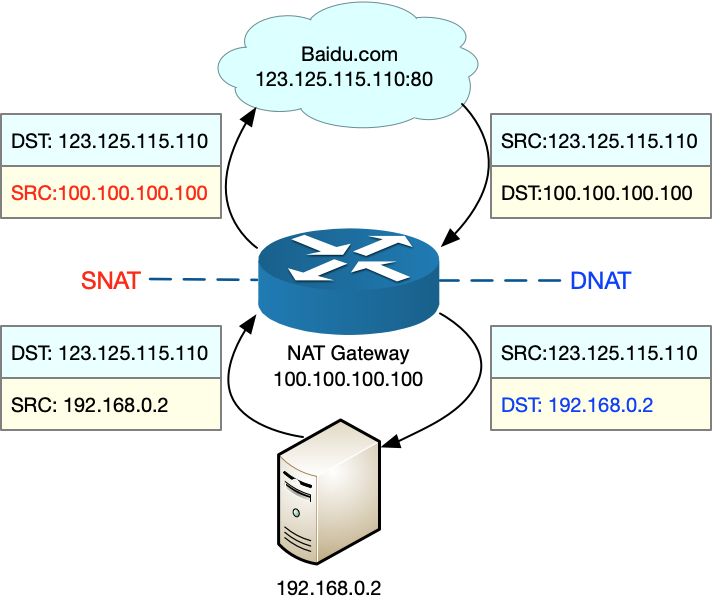
NAT 可以重新 IP 数据包的源 IP 或目的 IP,用来解决公网中 IP 地址短缺问题。原理是内网中的多个机器共用一个公网 IP 来访问外网。
SNAT 和 DNAT 示例:
2 iptables 与 NAT
Linux 支持 4 种表,包括 filter(用于过滤)、nat(用于 NAT)、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。
nat 表中内置了三个链:
- PREROUTING,用于路由判断前所执行的规则,比如,对接收到的包进行 DNAT。
- POSTROUTIG,用于路由判断后执行的规则,比如,对发送或转发的数据包进行 SNAT 或 MASQUERADE。
- OUTPUT,类似 PREROUTING,但只处理从本机发送出去的包。
3 管理 NAT 规则
在使用 iptables 配置 NAT 规则时,Linux 需要转发来自其它 IP 的网络包,所以需要开启 Linux 的 IP 转发功能,查看是否开启:
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1输出结果是 1,表示已经开启。
如果没有开启,可以手动开启:
$ sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1写到 /etc/sysctl.conf 文件中后,重启仍然会生效。
3.1 SNAT
为一个子网统一配置 SNAT,并由 Linux 选择默认的出口 IP:
$ iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE为具体的 IP 地址配置 SNAT,并指定转换后的源地址:
$ iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.1003.2 DNAT
$ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.24 现象
压测场景下,并发请求数大大降低:
# -c 表示并发请求数为5000,-n 表示总的请求数为 10 万
# -r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 30s
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
...
Requests per second: 76.47 [#/sec] (mean)
Time per request: 65380.868 [ms] (mean)
Time per request: 13.076 [ms] (mean, across all concurrent requests)
Transfer rate: 44.79 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1300 5578.0 1 65184
Processing: 0 37916 59283.2 1 130682
Waiting: 0 2 8.7 1 414
Total: 1 39216 58711.6 1021 130682
...每秒 74 个请求,每个请求延迟为 65s
5 排查
本文从 NAT 的角度排查。NAT 正常工作至少需要两个步骤:
- 利用 Netfilter 中的钩子函数(hook)修改源地址后目标地址。
- 利用连接跟踪模块 conntrack 关联同一个连接的请求和响应。
SystemTap 是 Linux 的一种动态追踪框架,它把用户提供的脚本转换为内核模块来执行,用来检测和跟踪内核的行为。
创建一个 dropwatch.stp 脚本:
#! /usr/bin/env stap
############################################################
# Dropwatch.stp
# Author: Neil Horman <nhorman@redhat.com>
# An example script to mimic the behavior of the dropwatch utility
# http://fedorahosted.org/dropwatch
############################################################
# Array to hold the list of drop points we find
global locations
# Note when we turn the monitor on and off
probe begin { printf("Monitoring for dropped packets\n") }
probe end { printf("Stopping dropped packet monitor\n") }
# increment a drop counter for every location we drop at
probe kernel.trace("kfree_skb") { locations[$location] <<< 1 }
# Every 5 seconds report our drop locations
probe timer.sec(5)
{
printf("\n")
foreach (l in locations-) {
printf("%d packets dropped at %s\n",
@count(locations[l]), symname(l))
}
delete locations
}执行 stap 命令,运行丢包跟踪脚本:
$ stap --all-modules dropwatch.stp
Monitoring for dropped packets切换终端再次执行 ab 压测命令后,观察 stap 的输出:
10031 packets dropped at nf_hook_slow
676 packets dropped at tcp_v4_rcv
7284 packets dropped at nf_hook_slow
268 packets dropped at tcp_v4_rcv大量的丢包发生在 nf_hook_slow 上,这是在 Netfilter Hook 的钩子函数中出现丢包问题了,但还不能是否是 NAT。接下来使用 perf 跟踪 nf_hook_slow 的执行过程。
再次执行 ab 命令后,切换终端执行 perf:
# 记录一会(比如30s)后按Ctrl+C结束
$ perf record -a -g -- sleep 30
# 输出报告
$ perf report -g graph,0在 perf report 界面中查找 hf_hook_slow,再展开调用堆栈,可以看到如下调用图:
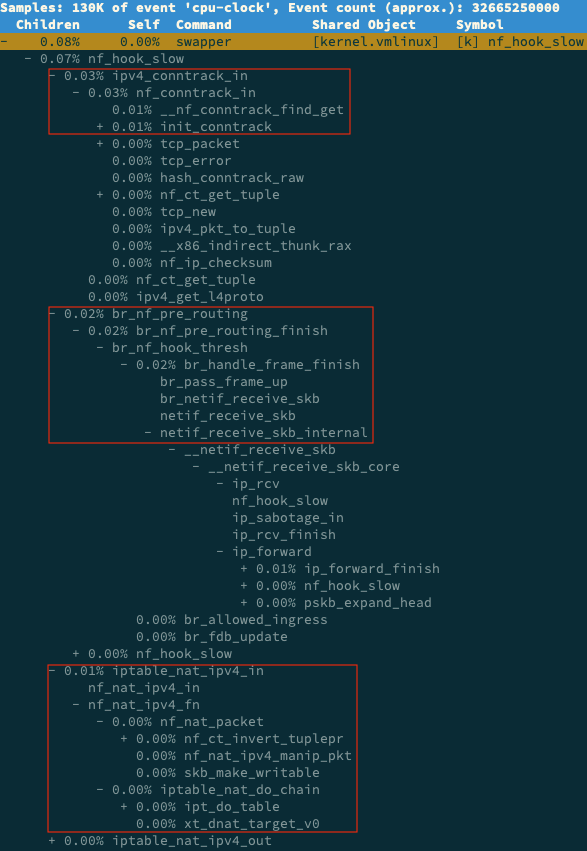
可以看到 nf_hook_slow 调用最多的有 3 个地方,分别是 ipv4_conntrack_in、br_nf_pre_routing 以及 iptable_nat_ipv4_in。说明 nf_hook_slow 主要执行 3 个动作:
- 接收网络包时,在连接跟踪表中查找连接,并为新的连接分配跟踪对象。
- 在网桥中转发包。这是因为本文中的 Nginx 运行在容器中,而容器的网络通过网桥实现。
- 接收网络包时,执行 DNAT,即把 8080 端口收到的包转发给容器。
以上是性能下降的 3 个来源,而这 3 个来源都是 Linux 内核机制,所以接下来的优化从内核入手。
DNAT 的基础是 conntrack,查看内核提供了哪些 conntrack 配置项:
$ sysctl -a | grep conntrack
net.netfilter.nf_conntrack_count = 180
net.netfilter.nf_conntrack_max = 1000
net.netfilter.nf_conntrack_buckets = 65536
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
...最重要的 3 个指标:
- net.netfilter.nf_conntrack_count,表示当前连接跟踪数,为 180;
- net.netfilter.nf_conntrack_max,表示最大连接跟踪数,为 1000;
- net.netfilter.nf_conntrack_buckets,表示连接跟踪表的大小,为 65535。
ab 命令中,并发请求数是 5000,请求数是 100000,而跟踪表中只记录 1000 个连接,是远远不够的。
实际上,内核异常时,会将异常信息记录到日志中,执行 dmesg 即可看到:
$ dmesg | tail
[104235.156774] nf_conntrack: nf_conntrack: table full, dropping packet
[104243.800401] net_ratelimit: 3939 callbacks suppressed
[104243.800401] nf_conntrack: nf_conntrack: table full, dropping packet
[104262.962157] nf_conntrack: nf_conntrack: table full, dropping packet可以适当调大连接跟踪数(连接跟踪数过大会耗费内存):
$ sysctl -w net.netfilter.nf_conntrack_max=131072
$ sysctl -w net.netfilter.nf_conntrack_buckets=65536重新执行 ab 命令后,结果比之前好了很多。
也可以查看连接跟踪表内容:
# -L 表示列表,-o 表示以扩展格式显示
$ conntrack -L -o extended | head
ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1
ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1统计连接:
# 统计总的连接跟踪数
$ conntrack -L -o extended | wc -l
14289
# 统计TCP协议各个状态的连接跟踪数
$ conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}'
SYN_RECV 4
CLOSE_WAIT 9
ESTABLISHED 2877
FIN_WAIT 3
SYN_SENT 2113
TIME_WAIT 9283
# 统计各个源IP的连接跟踪数
$ conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10
14116 192.168.0.2
172 192.168.0.96大部分的 TCP 连接都处于 TIME_WAIT 状态,它们大部分来源于 192.168.0.2 这个 IP
TIME_WAIT 的连接跟踪记录,会在超时后清理,而默认的超时时间是 120s:
$ sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120参考
倪朋飞. Linux 性能优化实战.


没有评论