这篇文章上次修改于 1403 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
在排查网络问题时,经常会碰到的一个问题是,内核的 CPU 利用率较高。比如高并发场景下,内核线程 ksoftrqd 的 CPU 使用率就会比较高,是网络收发的软中断导致的。接下来看下如何分析内核线程的性能问题。
1 内核线程
Linux 启动中有 3 个特殊的进程:
- 0 号进程为 idle 进程,在初始化完 1 号和 2 号进程后演变为空闲任务。
- 1 号进程为 init 进程,通常是 systemd 进程,在用户态运行,管理其他的用户态进程。
- 2 号进程 kthreadd 进程,在内核态运行,管理内核线程。
所以要查找内核线程,从 2 和进程开始,找它的子孙即可:
$ ps -f --ppid 2 -p 2
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 12:02 ? 00:00:01 [kthreadd]
root 9 2 0 12:02 ? 00:00:21 [ksoftirqd/0]
root 10 2 0 12:02 ? 00:11:47 [rcu_sched]
root 11 2 0 12:02 ? 00:00:18 [migration/0]
...
root 11094 2 0 14:20 ? 00:00:00 [kworker/1:0-eve]
root 11647 2 0 14:27 ? 00:00:00 [kworker/0:2-cgr]容易发送性能问题的内核线程:
- kswapd0:用于内存回收。
- kworker:执行内核工作队列,分为绑定 CPU 和未绑定 CPU 两类。
- migration:负载均衡过程中,将进程迁移到 CPU 上。每个 CPU 都有一个 migration 内核线程。
- jbd2/sda1-8:journaling blocking device,为文件系统提供日志功能。sda1-8 表示磁盘分区和设备号。每个使用 ext4 文件系统的磁盘分区都有一个 jbd2 内核线程。
- pdflush:将内存中的脏页写入磁盘。已在 3.10 中和入到 kworker 中。
2 现象
运行 hping3 命令,模拟客户端请求:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u10 表示每隔 10 微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把 10 调小,比如调成 5 甚至 1
$ hping3 -S -p 80 -i u10 192.168.0.30观察系统和进程 CPU 使用情况:
$ top
top - 08:31:43 up 17 min, 1 user, load average: 0.00, 0.00, 0.02
Tasks: 128 total, 1 running, 69 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.3 us, 0.3 sy, 0.0 ni, 66.8 id, 0.3 wa, 0.0 hi, 32.4 si, 0.0 st
%Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 34.5 si, 0.0 st
KiB Mem : 8167040 total, 7234236 free, 358976 used, 573828 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7560460 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 S 7.0 0.0 0:00.48 ksoftirqd/0
18 root 20 0 0 0 0 S 6.9 0.0 0:00.56 ksoftirqd/1
2489 root 20 0 876896 38408 21520 S 0.3 0.5 0:01.50 docker-containe
3008 root 20 0 44536 3936 3304 R 0.3 0.0 0:00.09 top
1 root 20 0 78116 9000 6432 S 0.0 0.1 0:11.77 systemd
...两个 CPU 的软中断都超过了 30%,而 CPU 使用率最高的正好是两个软中断内核线程 ksoftrqd/0、ksoftrqd/1。我们知道大概是因为大量的网络收发导致的,但是它到底在执行什么逻辑,我们却不知道,而 strace、pstack、lsof 等工具不适合内核线程。
3 排查
3.1 perf 分析
可以用 perf 分析一下进程号为 9 的 ksoftrqd:
# -a 表示追踪所有的 CPU
# -g 表示额外记录函数调用关系
# -- sleep 30 表示采样 30s 后退出
$ perf record -a -g -p 9 -- sleep 30继续执行 perf report,按上下方向键以及回车键,展开比例最高的 ksoftirqd,就可以得到如调用关系:
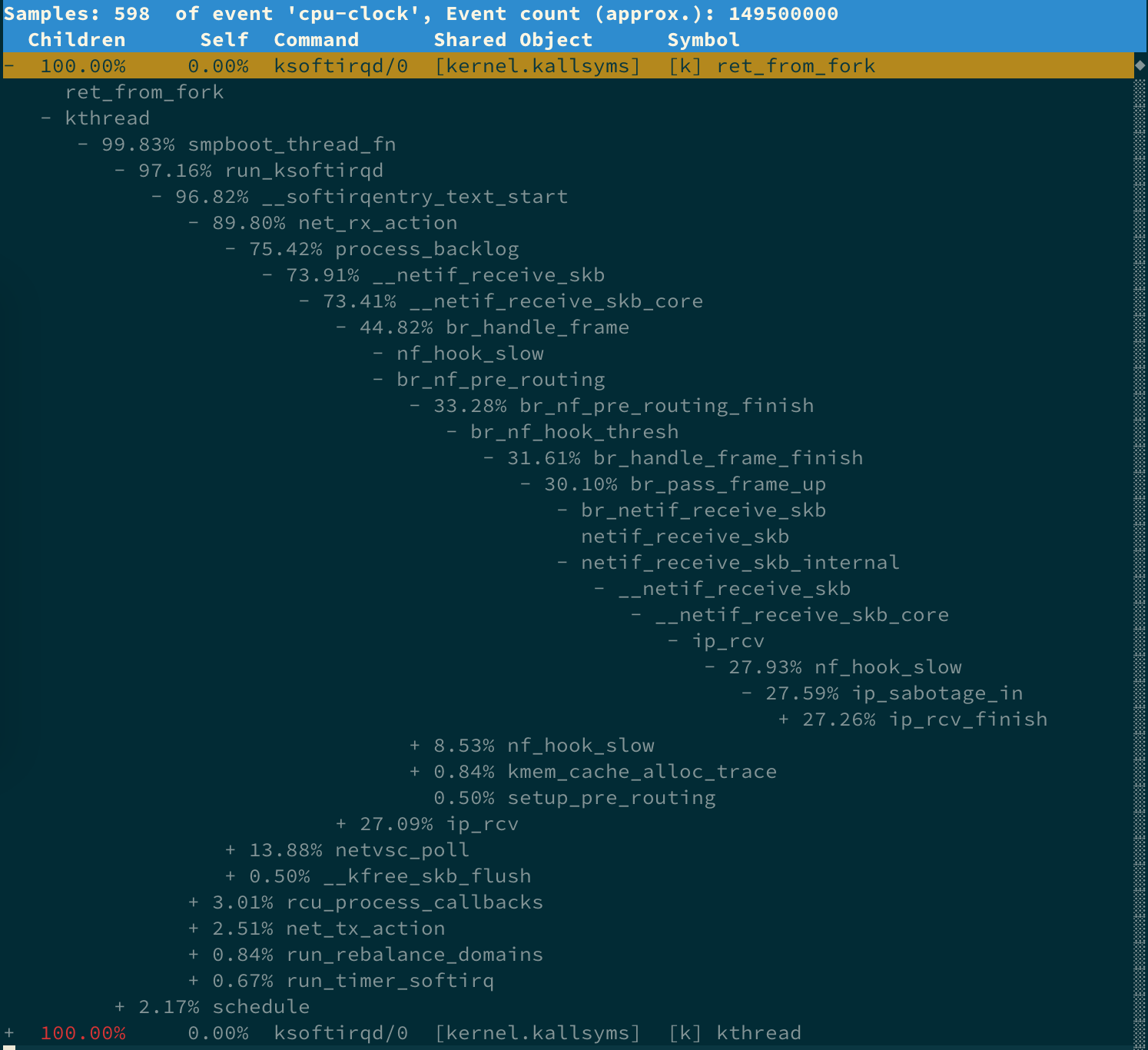
- net_rx_action 和 netif_receive_skb,表明这是接收网络包。
- br_handle_frame,表明网络包经过了网桥。
- br_nf_pre_routing,表明在网桥上执行了 netfilter 的 PREROUTING,可能有 DNAT 发生。
- br_pass_frame_up,表明网桥处理后,再交给其桥接的其他桥接网卡进一步处理。
这时因为服务跑在 docker 容器中,而 docker 容器会自动为容器创建虚拟网卡、桥接到 docker 的网桥并配置 NAT 规则。
3.2 火焰图分析
可以根据 perf record 生成的 perf.data 来生成火焰图。
下载火焰图工具:
$ git clone https://github.com/brendangregg/FlameGraph
$ cd FlameGraph生成火焰图:
$ perf script -i perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > ksoftirqd.svg使用浏览器打开 ksoftrqd.svg:
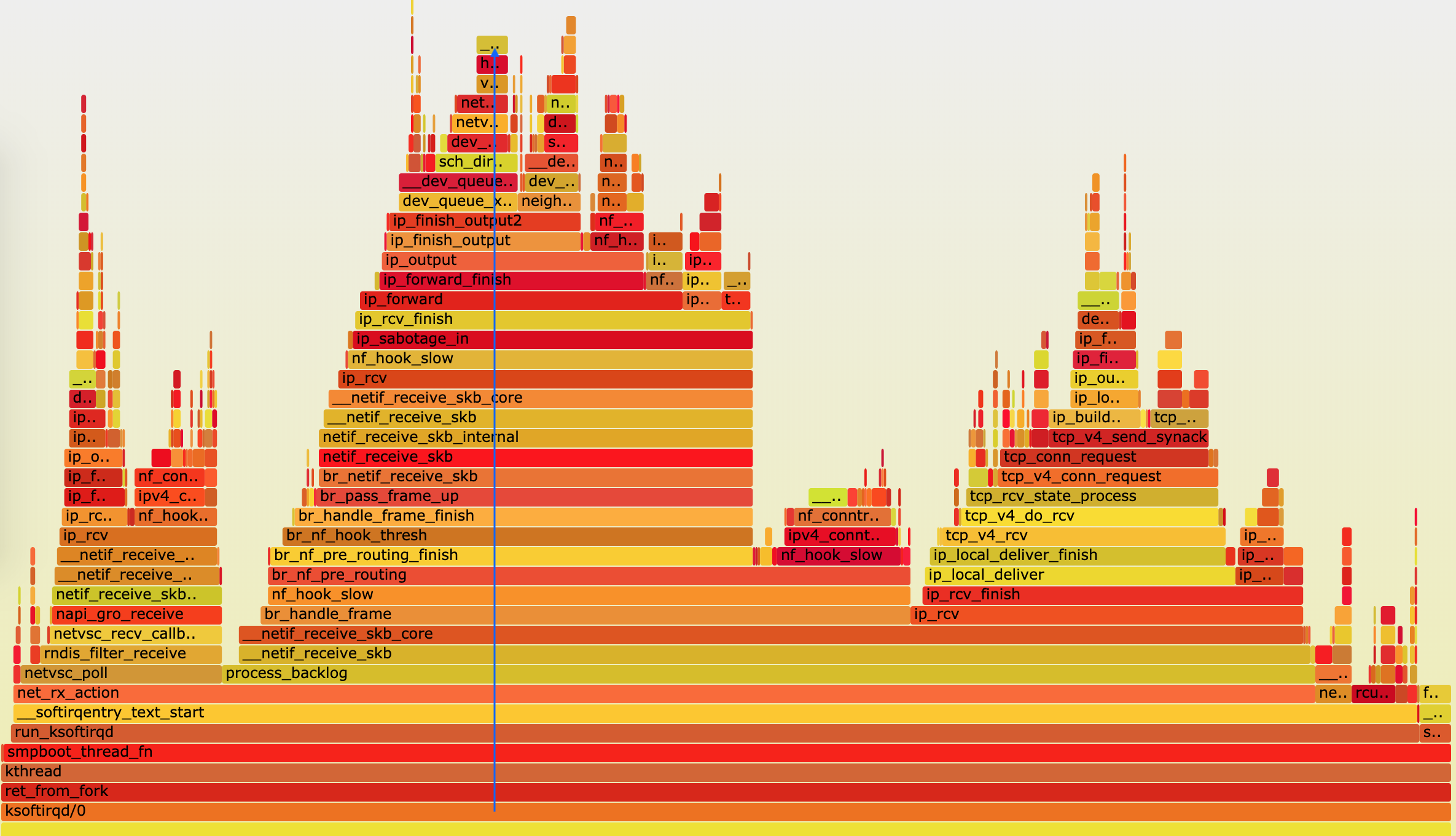
火焰图介绍:
- 横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。
- 纵轴表示调用栈,由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。
- 火焰图不包含任何时间因素,所以无法看出各函数的执行次序。
火焰图分析:
- 最开始,还是 net_rx_action 到 netif_receive_skb 处理网络收包;
- 然后, br_handle_frame 到 br_nf_pre_routing ,在网桥中接收并执行 netfilter 钩子函数;
- 再向上, br_pass_frame_up 到 netif_receive_skb ,从网桥转到其他网络设备又一次接收。
- 如果要进一步查看 TCP 相关的调用,可以点击上图左上角的“Reset Zoom”,回到完整火焰图中,再去查看其他小火焰的堆栈。
到这里,我们就找出了内核线程 ksoftirqd 执行最频繁的函数调用堆栈,而这个堆栈中的各层级函数,就是潜在的性能瓶颈来源。这样,后面想要进一步分析、优化时,也就有了根据。
参考
倪鹏飞. Linux 性能优化实战.


没有评论