这篇文章上次修改于 1412 天前,可能其部分内容已经发生变化,如有疑问可询问作者。
1 现象
查看服务性能:
# 默认测试时间为 10s,请求超时 2s
$ wrk --latency -c 1000 http://192.168.0.30
Running 10s test @ http://192.168.0.30
2 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 14.82ms 42.47ms 874.96ms 98.43%
Req/Sec 550.55 1.36k 5.70k 93.10%
Latency Distribution
50% 11.03ms
75% 15.90ms
90% 23.65ms
99% 215.03ms
1910 requests in 10.10s, 573.56KB read
Non-2xx or 3xx responses: 1910
Requests/sec: 189.10
Transfer/sec: 56.78KB吞吐量只有 189,并且所有 1910 个请求收到的都是异常响应(非 2xx 或 3xx)。吞吐量太低了,并且请求处理都失败了。
根据 wrk 输出的统计结果,可以看到总共传输的数据量只有 573 KB,肯定不是带宽受限导致的。所以,应该从请求数的角度来分析。
2 排查
2.1 连接数优化
分析请求数,特别是 HTTP 的请求数,可以从 TCP 连接数入手。
将测试延长到 30min:
$ wrk --latency -c 1000 -d 1800 http://192.168.0.30在另一个终端中观察 TCP 连接数:
$ ss -s
Total: 177 (kernel 1565)
TCP: 1193 (estab 5, closed 1178, orphaned 0, synrecv 0, timewait 1178/0), ports 0
Transport Total IP IPv6
* 1565 - -
RAW 1 0 1
UDP 2 2 0
TCP 15 12 3
INET 18 14 4
FRAG 0 0 0wrk 并发 1000 请求时,建立连接数只有 5,而 closed 和 timewait 状态的连接则有 1100 多。
内核中的连接跟踪模块,有可能会导致 timewait 问题。服务运行在 Docker 内,而 Docker 使用的 iptables ,就会使用连接跟踪模块来管理 NAT。
通过 dmesg 查看系统日志,如果有连接跟踪出了问题,应该会看到 nf_conntrack 相关的日志:
$ dmesg | tail
[88356.354329] nf_conntrack: nf_conntrack: table full, dropping packet
[88356.354374] nf_conntrack: nf_conntrack: table full, dropping packet
查看当前连接跟踪数和最大限制:
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 200
$ sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 200连接跟踪数最大限制只有 200,且全部被占了。
将 nf_conntrack_max 增大:
# 将连接跟踪限制增大到 1048576
$ sysctl -w net.netfilter.nf_conntrack_max=1048576重新测试 nginx 性能:
# 默认测试时间为 10s,请求超时 2s
$ wrk --latency -c 1000 http://192.168.0.30
...
54221 requests in 10.07s, 15.16MB read
Socket errors: connect 0, read 7, write 0, timeout 110
Non-2xx or 3xx responses: 45577
Requests/sec: 5382.21
Transfer/sec: 1.50MB吞吐量已经从刚才的 189 增大到了 5382。看起来性能提升了将近 30 倍,但是有 4 万多响应异常,即真正成功的只有 8000 多个。
2.2 工作进程优化
由于这些响应并非 Socket error,说明 Nginx 已经收到了请求,只不过,响应的状态码并不是我们期望的 2xx (表示成功)或 3xx(表示重定向)。所以,需要搞清楚 Nginx 真正的响应。
查看 nginx 容器日志:
$ docker logs nginx --tail 3
192.168.0.2 - - [15/Mar/2019:2243:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-"
192.168.0.2 - - [15/Mar/2019:22:43:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-"
192.168.0.2 - - [15/Mar/2019:22:43:27 +0000] "GET / HTTP/1.1" 499 0 "-" "-" "-"响应状态码为 499,并非标准的 HTTP 状态码,而是由 Nginx 扩展而来,表示服务器端还没来得及响应时,客户端就已经关闭连接了。即服务器端处理太慢,客户端因为超时(wrk 超时时间为 2s),主动断开了连接。
服务是 nginx + php,会不会是 php 比较慢,查看 php 容器日志:
$ docker logs phpfpm --tail 5
WARNING: [pool www] server reached max_children setting (5), consider raising it
WARNING: [pool www] server reached max_children setting (5), consider raising it建议增大 max_children,max_children 表示 php-fpm 子进程的最大数量。一般来说,每个 php-fpm 子进程可能会占用 20 MB 左右的内存。所以,可以根据内存和 CPU 个数,估算一个合理的值,本文设置成了 20。切换终端,再次测试 nginx 性能:
# 默认测试时间为 10s,请求超时 2s
$ wrk --latency -c 1000 http://192.168.0.30
...
47210 requests in 10.08s, 12.51MB read
Socket errors: connect 0, read 4, write 0, timeout 91
Non-2xx or 3xx responses: 31692
Requests/sec: 4683.82
Transfer/sec: 1.24MB成功的请求数多了不少,从原来的 8000,增长到了 15000(47210-31692=15518)。但是 4000 多的吞吐量显然还是比较差。如何进一步提升吞吐量呢?
2.3 套接字优化
还是用 -d 参数延长测试时间,以便模拟性能瓶颈的现场:
# 测试时间 30 分钟
$ wrk --latency -c 1000 -d 1800 http://192.168.0.30观察有没有丢包:
# 只关注套接字统计
$ netstat -s | grep socket
73 resets received for embryonic SYN_RECV sockets
308582 TCP sockets finished time wait in fast timer
8 delayed acks further delayed because of locked socket
290566 times the listen queue of a socket overflowed
290566 SYNs to LISTEN sockets dropped
# 稍等一会,再次运行
$ netstat -s | grep socket
73 resets received for embryonic SYN_RECV sockets
314722 TCP sockets finished time wait in fast timer
8 delayed acks further delayed because of locked socket
344440 times the listen queue of a socket overflowed
344440 SYNs to LISTEN sockets dropped根据两次统计结果中 socket overflowed 和 sockets dropped 的变化,可以看到,有大量的套接字丢包,并且丢包都是套接字队列溢出导致的。所以,接下来,我们应该分析连接队列的大小是不是有异常。
查看套接字队列大小:
$ ss -ltnp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 10 10 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=10491,fd=6),("nginx",pid=10490,fd=6),("nginx",pid=10487,fd=6))
LISTEN 7 10 *:9000 *:* users:(("php-fpm",pid=11084,fd=9),...,("php-fpm",pid=10529,fd=7))Nginx 和 php-fpm 的监听队列 (Send-Q)只有 10,而 nginx 的当前监听队列长度 (Recv-Q)已经达到了最大值,php-fpm 也已经接近了最大值。
套接字监听队列长度既可以在应用程序中,通过套接字接口调整,也支持通过内核选项来配置。分别查询 Nginx 和内核选项对监听队列长度的配置:
# 查询 nginx 监听队列长度配置
$ docker exec nginx cat /etc/nginx/nginx.conf | grep backlog
listen 80 backlog=10;
# 查询 php-fpm 监听队列长度
$ docker exec phpfpm cat /opt/bitnami/php/etc/php-fpm.d/www.conf | grep backlog
; Set listen(2) backlog.
;listen.backlog = 511
# somaxconn 是系统级套接字监听队列上限
$ sysctl net.core.somaxconn
net.core.somaxconn = 10需增大以上三个值,比如,可以把 Nginx 和 php-fpm 的队列长度增大到 8192,而把 somaxconn 增大到 65536。重新测试 nginx 性能:
$ wrk --latency -c 1000 http://192.168.0.30
...
62247 requests in 10.06s, 18.25MB read
Non-2xx or 3xx responses: 62247
Requests/sec: 6185.65
Transfer/sec: 1.81MB吞吐量已经增大到了 6185,并且执行 netstat 时没有丢包问题了,但是请求全部失败了,查看 nginx 日志:
$ docker logs nginx --tail 10
[crit] 15#15: *999779 connect() to 127.0.0.1:9000 failed (99: Cannot assign requested address) while connecting to upstream, client: 192.168.0.2, server: localhost, request: "GET / HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.0.30"Nginx 报出了无法连接 fastcgi 的错误,错误消息是 Connect 时, Cannot assign requested address。这个错误消息对应的错误代码为 EADDRNOTAVAIL,表示 IP 地址或者端口号不可用。接下来分析端口号的问题。
2.4 端口号优化
当客户端连接服务器端时,需要分配一个临时端口号。查询系统配置的临时端口号范围:
$ sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range=20000 20050临时端口的范围只有 50 个,增大端口号范围:
$ sysctl -w net.ipv4.ip_local_port_range="10000 65535"再次测试性能:
$ wrk --latency -c 1000 http://192.168.0.30/
...
32308 requests in 10.07s, 6.71MB read
Socket errors: connect 0, read 2027, write 0, timeout 433
Non-2xx or 3xx responses: 30
Requests/sec: 3208.58
Transfer/sec: 682.15KB异常的响应少了 ,但吞吐量下降到了 3208。并且,这次还出现了很多 Socket read errors。
2.5 火焰图
是不是其他系统资源遇到了瓶颈?
启动长时间测试:
# 测试时间 30 分钟
$ wrk --latency -c 1000 -d 1800 http://192.168.0.30观察 CPU 和内存使用:
$ top
...
%Cpu0 : 30.7 us, 48.7 sy, 0.0 ni, 2.3 id, 0.0 wa, 0.0 hi, 18.3 si, 0.0 st
%Cpu1 : 28.2 us, 46.5 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 23.3 si, 0.0 st
KiB Mem : 8167020 total, 5867788 free, 490400 used, 1808832 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7361172 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20379 systemd+ 20 0 38068 8692 2392 R 36.1 0.1 0:28.86 nginx
20381 systemd+ 20 0 38024 8700 2392 S 33.8 0.1 0:29.29 nginx
1558 root 20 0 1118172 85868 39044 S 32.8 1.1 22:55.79 dockerd
20313 root 20 0 11024 5968 3956 S 27.2 0.1 0:22.78 docker-containe
13730 root 20 0 0 0 0 I 4.0 0.0 0:10.07 kworker/u4:0-ev内存还是很充足的,系统 CPU 使用率(sy)比较高,两个 CPU 的系统 CPU 使用率都接近 50%,且空闲 CPU 使用率只有 2%。再看进程部分,CPU 主要被两个 Nginx 进程和两个 docker 相关的进程占用,使用率都是 30% 左右。
可以使用 perf 寻找系统中的热点函数:
# 执行perf记录事件
$ perf record -g
# 切换到 FlameGraph 安装路径执行下面的命令生成火焰图
$ perf script -i ~/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > nginx.svg用浏览器打开生成的 nginx.svg:
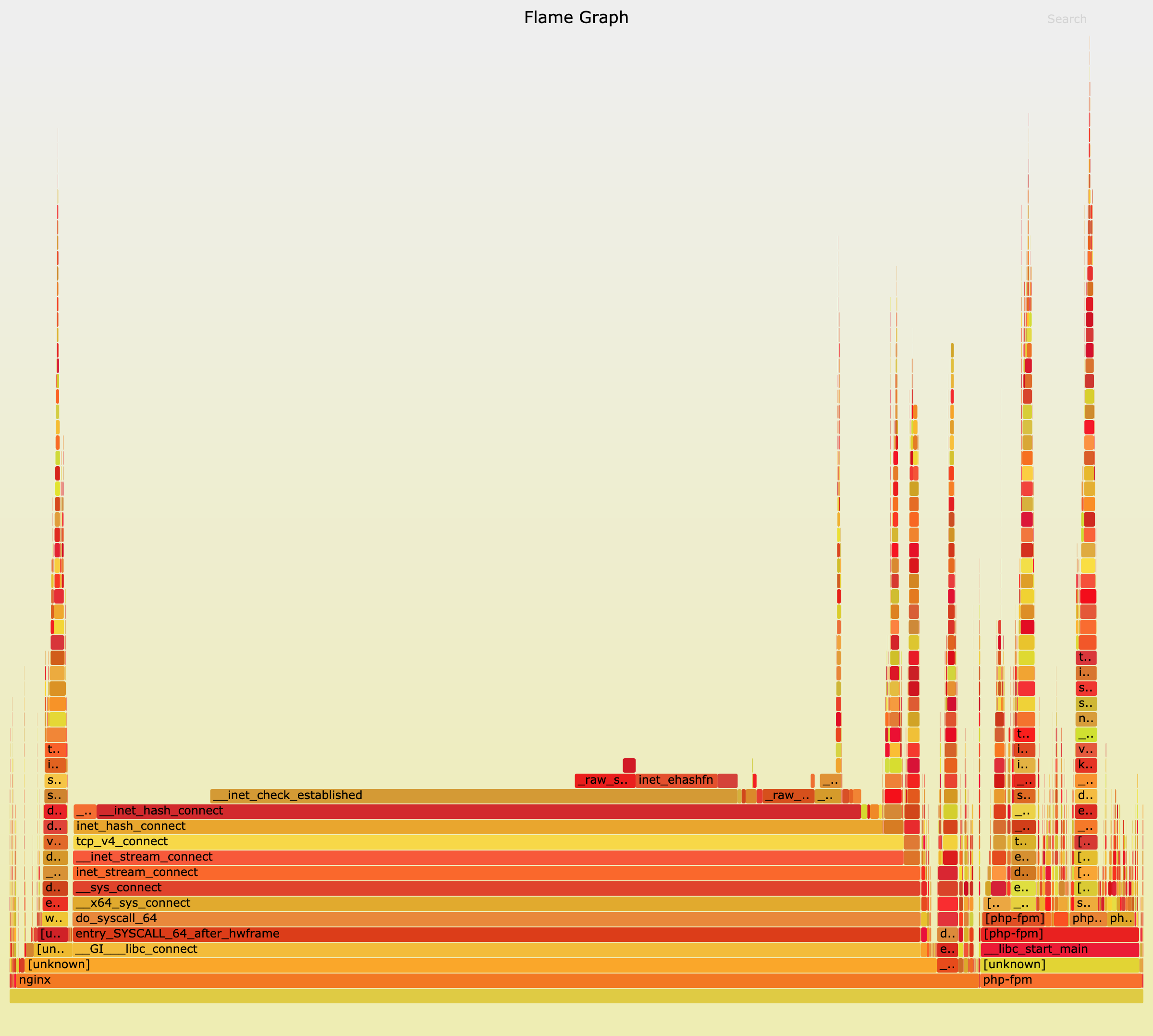
__init_check_established 函数是检查端口号是否可用。如果有大量连接占用着端口,那么检查端口号可用的函数,不就会消耗更多的 CPU 吗?查看连接状态统计:
$ ss -s
TCP: 32775 (estab 1, closed 32768, orphaned 0, synrecv 0, timewait 32768/0), ports 0
...有大量连接(32768)处于 timewait 状态,而 timewait 状态的连接会继续占用端口号。如果这些端口号可以重用,就可以缩短 __init_check_established 的过程。查看配置:
$ sysctl net.ipv4.tcp_tw_reuse
net.ipv4.tcp_tw_reuse = 0开启端口复用:
$ sysctl net.ipv4.tcp_tw_reuse=1重新测试 nginx 性能:
$ wrk --latency -c 1000 http://192.168.0.30/
...
52119 requests in 10.06s, 10.81MB read
Socket errors: connect 0, read 850, write 0, timeout 0
Requests/sec: 5180.48
Transfer/sec: 1.07MB吞吐量已经达到了 5000 多,并且只有少量的 Socket errors,也不再有 Non-2xx or 3xx 的响应了。
参考
倪鹏飞. Linux 性能优化实战.


没有评论